I have dedicated a portion of my portfolio to ‘picocap’ (under $50 million of market capitalization), over-the-counter-traded companies. This post is part of a series of reflections on beginning to invest in these companies.
Most traders and investors will be familiar with the idea of “NBBO”, or “national best bid and offer”, a Securities and Exchange Commission-created term that refers to the best bid for a particular stock across all exchanges, and the corresponding best offer.
That is, if the highest-price buy limit order placed is for $10.00 per share for 100 shares, and the lowest-price sell limit order placed is 100 shares for $10.02 per share, the NBBO is $10.00 x 1 - $10.02 x 1 (1 being short for 100 shares, or 1 lot).
However, in the wild west OTC markets, where the spread can easily be 10 or 20% of the share price, there’s a particular rule you should be familiar with - miniumum quotation sizes.
FINRA rule 6433 establishes minimum quotation sizes for orders.
To be posted, your order must be at least this large:
$0.0001-$0.0999 per share: 10,000 shares
$0.10 - $0.1999 per share - 5,000 shares
$0.20 - $0.5099 per share - 2,500 shares
$0.51 - $0.9999 per share - 1,000 shares
$1.00 - $174.99 per share - 100 shares
That is, if you enter a limit order for $0.50 per share for a stock for 1,000 shares, your order will not be posted to the market, unless, potentially, your order is combined with another equal-priced limit order at the same routing dealer - which, in these exchanges, is only somewhat likely. I don’t have a clear idea of how that would work.
Your limit order will still be accepted, though, so if the ask then crosses your limit, it’ll be executed - but presumably, you entered your limit buy because you didn’t just want to hit the ask.
There are several effects of this rule:
First, this establishes an effective dollar-minimum order size for investors who do not want to pay the spread:
$0.0001 - $0.0999 per share: up to $999
$0.10 - $0.1999 per share: $500 to $999.5
$0.20 - $0.5099 per share: $500 to $1274.75
$0.51 - $0.9999 per share: $510 to $999
$1.00 - $174.99 per share: $100 and up
That is, if you want to avoid paying the spread - which, remember, for these OTC stocks, can easily be 10-20% of the share price - you need to have, generally, about $1000 to $1250 to enter the position.
Second, certain normal behaviors, including partial fills, make trading much more expensive.
Consider a small trader who wants to open a minimum-sized position in a stock trading around $0.40 per share. He or she enters an order for 2500 shares at $0.4010 for 2,500 shares, for $1002.5 order size.
A few minutes later a market order for 2 lots comes through, giving a partial fill. This reduces the order size to 2,300 shares, putting it below the minimum size and taking it off the board.
At least with Fidelity, you cannot increase the share count for a partially filled limit order, so you are only left with the option of cancelling the order and entering a new one, which means paying two commissions - effectively paying a $4.95 commission for a 200 share, $80 order.
To deal with this, you may consider entering orders that are larger than the position you may want to open, and cancelling them if you end up with a partial fill. Ideally, this order would be at least twice the minimum, so in the event of a full fill, you can post a minimum-size ask and maybe make the spread.
Finally, you may consider asking your broker about the exact minutiae of their order-edit rules and how commission is charged, to avoid over-paying for many partial fills on limit orders.
This post will likely become out of date very shortly as Amplify Improves. If it has been more than 2 months since this post, please consider this “reader beware”.
A few months ago, I noted how wonderful I found AWS Amplify. Since then, Amplify has only improved.
Amplify is a JavaScript library and CLI toolkit that (1) brings together several existing AWS serverless products into one easy-to-use package in your front end, and (2) provides an easy way to set up and manage the backend infrastructure those front end features would rely on.
With Amplify, you can get an almost Rails + Heroku like experience, e.g. using amplify add auth to add authentication to your application from front end through AWS Identity pool, amplify add hosting to set up S3 or S3 + CloudFront based hosting for the static assets of the site, and “amplify publish” to both deploy Amplify-generated CloudFront setups and simultaneously push static code to S3, much like heroku push.
Amplify additionally has some associated libraries to better integrate Amplify with popular front end JavaScript frameworks like React and Angular.
However, I had some trouble getting Amplify set up with React, ES6, and Webpack. I believe that at this time there are several library versions that are in flux, meaning that many existing tutorials are out of date.
At the time of writing, this should give you a functional setup. First, set up a new project with NPM. Note that this does not include the aws-amplify-react package.
First, install the amplify CLI, per the Amplify Quick Start and configure Amplify:
12
npm install -g @aws-amplify/cli
amplify configure
Then make a basic folder structure - you can just ‘touch’ index.html and ‘package.json’.
Note that we’re using Babel 6 here. At the time of writing, Babel 7 had been released. Babel 7 renames several of the babel packages - for example, babel-runtime becomes @babel/runtimesee package. However, at least to the best of my knowledge, there is some dependency in the React and / or aws-amplify packages that prevents using webpack + babel 7 + react + amplify together.
Once this is in, add the following scripts to your package.json:
Note that the key aspects here are: adding ‘.js’ and ‘.jsx’ to your resolve: extensions section, and adding the ‘CopyWebpackPlugin’ to your ‘plugins’ section.
To use this setup, you need an index.html in your project root that references ‘bundle.js’. You’ll need a file entrypoint in ‘src/app.js’ that will be compiled to ‘bundle.js’. In ‘src/app.js’, you can use the following imports:
1234
import React from 'react';
import ReactDom from 'react-dom';
import Amplify from 'aws-amplify';
import awsmobile from './aws-exports';
Once this is done, you can add hosting with amplify add hosting, and then push any changes you’ve made to your app with amplify publish.
Preface: I’ve become obsessed with Wardley Maps. Wardley maps are true maps - that is, planes with direction and movement - that help you understand the implications of a business’ strategy. If you’re not familiar with them, I recommend reading Simon Wardley’s WIP book on Medium or trying Ben Mosior’s Build your First Wardley Map.
Wardley maps have become an important part of my decision making toolkit. I use them to understand & communicate the strategic considerations of companies I interact with.
However, the strategic implications of Wardley maps can come into opposition with other decision making tools. Whenever we see contradictions from trusted rules, we must dive deeper - either one of our tools is broken, or we’re not seeing the whole situation.
In this post, I’ll consider what we’re missing when the Wardley Map contradicts a capital budgeting rule, like the IRR rule.
This post will assume you are familiar with Wardley Maps. It will also assume you understand the IRR rule. If you are unfamiliar with the IRR rule, see a brief explanation at the bottom of this post 1.
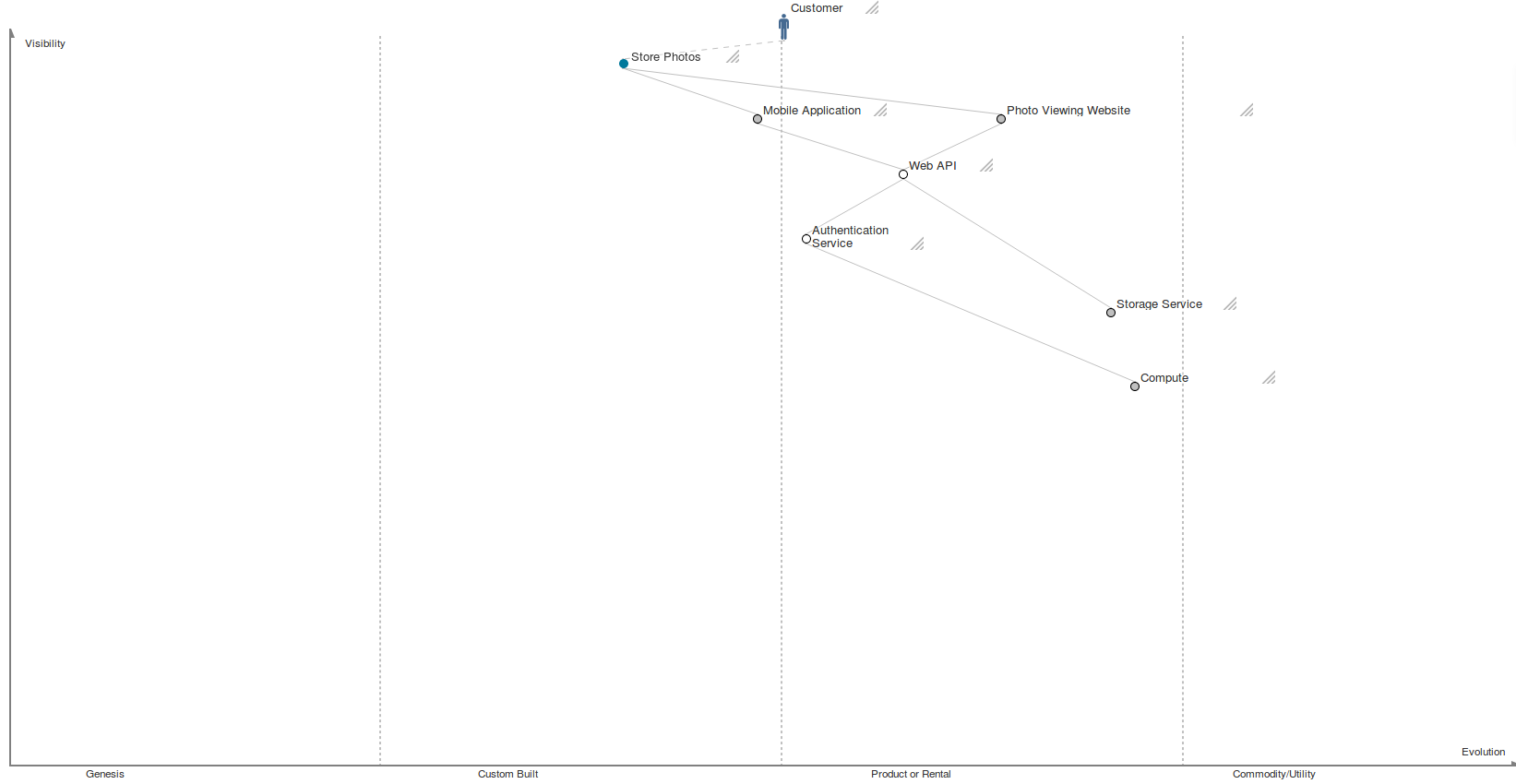
Let’s say we’re Dropbox, and we’re evaluating a proposal to invest significantly in building our own storage service, and move off of AWS. The IRR rule works out - at least on our projects, we can invest some reasonable amount, and save immensely on our AWS bills.
But building a custom replacement for Amazon S3 is replacing something that is at least a ‘product’, if not a utility, with a custom-build option. That is moving our dependency to the left on the Wardley map - against the grain of history! By doing so, we’ll lose out, or have to pay to keep up with, any benefits that would accrue naturally over time, as components move rightwards on the map.
Let’s assume that we’ve already negotiated as hard as we can against Amazon, and that we can’t get a suitable quote from any other provider (replacing S3 with another competing service would not imply changing our map, and so there would be no conflict, and negotiating well is just good business sense).
We appear to be in a dilemma: either (a) our Wardley Map is steering us wrong, and custom built is the way, (b) our IRR rule is no good, and we should keep paying Amazon for S3.
I propose that in this situation, our cost of capital is too low. We should find ways to increase our cost of capital, by adding risk, by developing new products, by buying back equity.
Consider how the cost of capital varies with the x-axis of the Wardley map. To the left, in the Genesis and Custom Built zones, we have high risk and high uncertainty. Our cost of capital is high. As we move rightwards, towards utilities, our cost of capital should decrease - building a new power plant can be done for practically zero cost of capital, with government bonds.
Consider Dropbox’s map above. Like maps for most companies, the end user need that is being fulfilled is leftwards of many of the internal dependencies. That is, the cost of capital for the business as a whole should be higher than the cost of capital for some of the internal dependencies, considered in isolation. If our cost of capital happens to be such that it looks like we can make profitable but non-strategic investments low in our value chain, it must be because our cost of capital is that of a more mature company than we actually are - and we should increase our cost of capital (share buybacks! dividends!) to compensate; not tilt the windmill of building a custom utility.
If you are unfamiliar, the IRR rule is this: when a company decides how to invest (that is, how to allocate or budget capital), it should consider each project’s Internal Rate of Return - that is, the expected return from the results of the investment - and compare it to the company’s cost of capital. If the IRR > Cost of Capital, then the project may be a good choice; if IRR < Cost of Capital, the project should not move forward. Fundamentally, the IRR rule expresses this: if the company makes this investment, do we expect to make profit in excess of our cost of capital? As an example, consider a company that makes TV remotes may consider to spend $1m on a new machine that will enable them to sell, after the cost of production and sales, an extra $200k’s worth of TV remotes each year for 5 years and then scrap the machine and recover $700k at the end of the 5th year. The internal rate of return of this project is 15.60%. If the company can borrow $1m from the bank for 7%, then 15.6% > 7%, and the investment should be made.↩
Some notes from setting up AWS Cognito for authentication on a new SPA, but turns into notes about AWS Amplify.
Some notes on setting up AWS Cogntio User Pools:
I have been using the AWS SDK for Javascript using Node as much as possible, instead of using the dashboard, in order to help keep steps reproducible.
Note that the aws-sdk library will default to use the [default] credentials configured in ~/.aws/credentials, and may fail silently to override them.
Note that it appears that Identity Pools created from the SDK will not appear on the dashboard until you have added a user. Alternatively, this may just be an artifact of eventual consistency on the API.
If you’re looking for the above, you should try Amplify
If you are interested in using AWS Cognito, I suggest you additionally look at AWS Amplify, which helps get you started with Cognito + several other AWS product in one neat package.
Note, however, that if you use the AWS Amplify CLI,
The default Cognito User Pool that is created will have a phone number and 2fa on
You cannot change the above setting.
As such, I suggest not creating a Cognito User Pool through the Amplify CLI; it makes local development far more painful than necessary.
Instead, create the Cognito User Pool through the dashboard or using a script.
If you are using Amplify, I’ve started to create a quickstart development environment, though note that it does not have a local stub of AWS Cognito User Pools.
Notes (‘epistemic status’): This post is conjecture and hypothesis; the purpose of this post is for me to work through ideas. No authority is claimed.
I am dissatisfied with my throughput as a product engineer 1.
While I hope and believe that I am at least an above-average developer, by throughput 2, in my tool sets of choice, I do not believe my throughput has increased
significantly in the last year. Additionally, I am troubled by a nagging feeling that there must be a better way to develop software.
As a (chiefly) Ruby programmer who has never used a strongly and statically typed language professionally, I have been exploring type systems, type theory, and
category theory in order to determine if a type system may enable significant throughput increases.
In theory, the benefits of a type system are (a) reducing programming errors, and revealing errors sooner, using the type system, and (b) for statically typed
languages, enabling more-powerful program analysis.
In practice, the benefits ability of a type system to reduce programming errors is restricted by the power 3 of the type system.
The benefits of more-powerful program analysis are reduced by poor tools, and made unnecessary by powerful language features 4.
What both of these amount to is: a type system can make a programmer more effective in managing complexity. Ideally, they help the programmer manage inherent complexity, the
complexity that is required by the problem.
The cost of a type system is incidental complexity. When programmers complain about the boilerplate that languages like Java and C++ force for defining interfaces,
they are complaining about having to manage complexity not inherent to the problem they are solving.
The “loss of flexibility” complaint is, in my mind, a symptom of extra incidental complexity; more complex systems are harder to change, regardless of whether the complexity is
incidental or inherent.
The question, then, is: does a type system provide more benefit in managing inherent complexity than it costs in incidental complexity?
When phrased this way, the problem is more clearly a matter of choice: a programmer’s method of managing complexity is personal to them.
I use the term ‘product engineer’ to mean ‘a software engineer who has and takes responsibility for designing product features as well’.↩
“Throughput” in the sense used by Eliyahu M. Goldratt in his books; I choose it to avoid the existing connotations and preconceptions of ‘productivity’.↩
No precise definition of ‘power’ or ‘powerful’, but a. A type system’s power increases with its ability to correctly and automatically infer types. b. A type system’s power increases with the quantity of restrictions that can be placed on a type. That is, Liquid Haskell’s refinement types are more powerful than regular Haskell types; Idris’ dependent types are more powerful than both, in terms of specificity. The two senses of power can be made to trade off against each other; whether Liquid Haskell’s type system is more powerful than Idris’ is a matter of debate, as I do not know how precisely weight Idris’ dependent types against Liquid Haskell’s much better automatic type inference.↩
“Powerful” language can be taken to be something like “expressive”; think of the trade off between Java with great IDE refactoring tools, and a ‘more powerful’ language like Ruby, where you rarely need to use those tools in the first place. The ability to manipulate the text of the language source easily is among the most powerful features. A good library for manipulating the AST of the language can substitute. This is why I consider lisp to be one of the most-powerful languages.↩